Fast and fuzzy client-side search with Lunr.js and Drupal
For a recent project a client asked us to investigate an "instant search" feature, where as the user begins to type, suggestions for matching pages appear immediately. The following post introduces the Search API Lunr module and how it solved this problem for us.
Lunr.js is an implementation of a search index written entirely in JavaScript. Using the library, you can generate an index of content and then query the index with search terms. The library supports a powerful ranking system, per-field boosting, partial and fuzzy matches as well as a plugin system for processing keywords during indexing and querying. This library turned out to be a good choice for the instant search feature, as well as the primary search interface for the site. The quality of search results returned from Lunr seems to stack up well against other solutions like Solr, when configured in similar fashion.
In order to integrate Lunr with Drupal, the existing Lunr search module was evaluated, however the architecture was based around pre-building a Lunr index and distributing that index to clients. While this has the advantage of speeding up searches and is more performant for users of static sites, it requires a long build process to take place when content is updated, either by the site editors in a browser or via Node.js running on the server. Additionally, as search results are matched by the index, the associated document is downloaded separately during rendering, which wasn't going to cut it for an instant search that is expected to provide immediate feedback.
Given the target site for this feature was an integrated Drupal back-end, the design goals were:
- Unaffected content authoring workflow for content editors, with no latency between content changing and results appearing in search.
- No additional Node.js dependency on the server.
- No additional dependency on a build process (ie, unattended content changes such as scheduled updates would continue to work).
- Indexing across multiple entity types and bundles.
To address these points, an alternative implementation based on a custom Search API back-end was created in the Search API Lunr module. The module manages to overcome some of the difficulty in creating a pre-built index by pushing the collection of documents to users, then allowing the browser of each user to build their own index. After indexing, the results are cached locally until such time as it needs to be rebuilt.
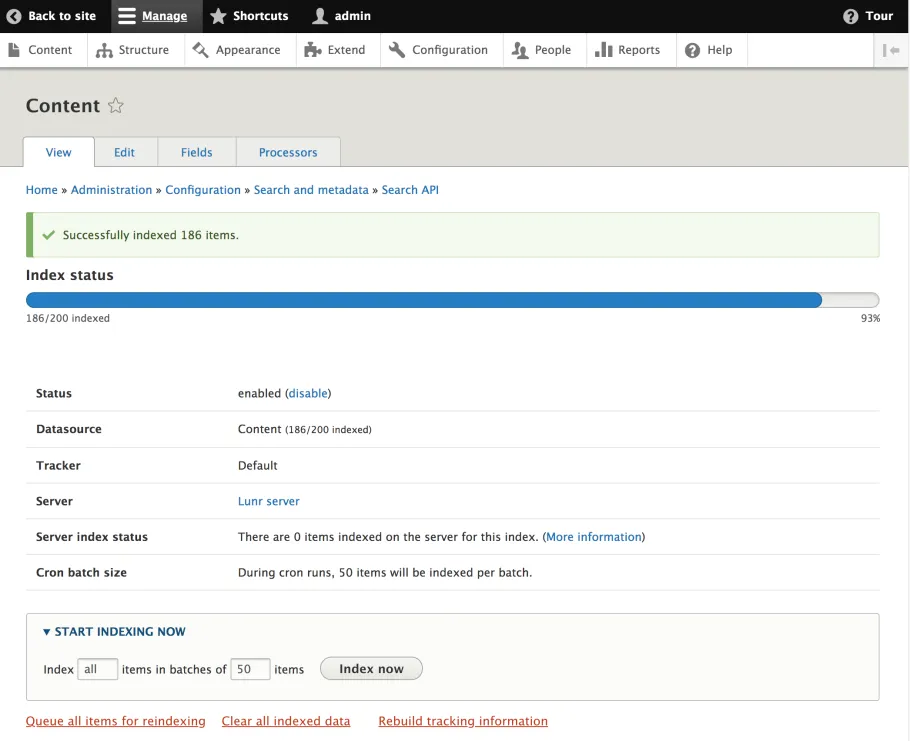
To build the collection of documents that are sent to the client, Search API can be used by developers in the same way as other back-ends are configured. Tasks such as the following can be performed as expected:
- Configuring which entity types and bundles appear in the index.
- Configuring which fields are indexed and the process pipeline applied to each.
- Administrative tasks such as flushing and rebuilding the index.
While requiring clients to generate a relatively expensive search index carries with it some practical limits, I've found it to perform with up to around 2000 or so large content pages generated with devel_generate. Putting it into action, the results of the instant search are relatively snappy and provide high quality results, even when given misspellings and partial words.
The JavaScript API shipped with the module is designed to give developers easy access to query and access documents from the index (which both the search page and block each consume for their functionality). To run a query against the Lunr index on any page or to gain direct access to the underlying hydrated Lunr.js object, developers only need the ID of the Search API server and index that was configured in Drupal. Here is a minimal example of the API in action, fetching a list of blog posts matching "foo", then firing an alert and redirecting to the first result:
(function(api) {
const blogIndex = api.getServer('lunr').getIndex('blog_content');
blogIndex.search('foo').then((results) => {
const firstResult = results.shift();
alert(`Found a blog post! ${firstResult.getLabel()}`);
window.location = firstResult.getUrl();
});
})(window.searchApiJs);
It's worth noting that any number of indexes can be configured and that downloading and indexing the documents only occurs when a query is actually executed. In the out of the box use case, no cost is incurred for any sessions that don't actually make use of search. For optimisation purposes, a light index (perhaps including only the titles of documents) could be built for the autocomplete feature, with a larger index only used once a search form is actually submitted.
The module is still in an early alpha state however feedback is always welcome. For sites with a small to medium number of pages, perhaps the module could be a useful tool for providing high quality search results, without the overhead of provisioning and maintaining additional infrastructure like Solr.